
티스토리 뷰
김종민 - Elastic 테크 에반젤리스트
Reference
Elastic Stack
ELK로 많이 알려져 있지만, 2015년 Beats가 합류하고, Elastic사에서 Stack들을 계속 추가하고 있기 때문에 공식적으로 Elastic Stack으로 명명하고있다.
Elasticsearch, Kibana, Logstash, Beats가 포함된다.
100% 오픈소스이며, Apache 2 라이센스로 제공
X - Pack
Elastic Stack과 별개의 확장팩으로 배포하는 상용 플러그인
기능은 Security, Alerting, Monitoring, Reporting, Graph Analytics, Machine Learning
Elastic Cloud
Elaticsearch 클러스터를 Cloud에서 SaaS 형태로 몇번의 클릭만으로 만들 수 있다.
Elastic Cloud Enterprise
추가적으로 기업 또는 거대한 조직에서 필요한 클라우드 서비스가 있는 경우 Elastic Cloud Enterprise 서비스를 이용할 수 있다.
IDC 또는 Private Network환경에서 Elastic Cloud Enterprise를 설치하면, 조직내의 서로 다른 부서에서 각각 다른 Elasticsearch환경이 필요하다고 할 때, 해당 환경에 맞는 Elastic 클러스터를 X-Pack이 포함된 상태로 생성할 수 있다.

Elasticsearch
Elasticsearch는 Elastic Stack의 심장이라고 불릴만큼 중요한 역할을 담당한다. Elasticsearch에 모든 데이터가 저장이 되며 검색, 쿼리 등 필요한 것들은 Elasticsearch에서 처리 된다.
특징
Distributed, Scalable
High-availability
Multi-tenancy
Developer Friendly
Real-time, Full-text Search
Aggregations
Today's Developer Requirements
Horizontal Scale
Real-Time Data Availability
Flexible Data Model
Rapid Query Execution
Sophisticated Query Langeage
Schemaless
Apache Lucene
하둡을 개발한 Doug Cutting에 의해 Java로 개발되었다.
Elasticsearch는 기본적으로 Apache Lucene이라는 라이브러리를 사용한다.
Lucene은 자체적으로 검색엔진을 만들 수 있지만, 라이브러리이기 때문에 이것을 Product로 개발하는 과정이 필요하다.
그렇게 만들어진 대표적인 Product가 Apache Solr와 Elasticsearch이다.
Elasticsearch 클러스터링
데이터들이 대용량으로 처리가 되기 때문에 클러스터링 환경을 필요로 한다.
Elasticsearch는 기본적으로 데이터를 샤드(Shard) 단위로 분리해서 저장한다.
샤드(Shard)는 Lucene 레벨의 검색 스레드이고, Elasticsearch의 실행 프로세스를 노드(Node)라고 표현한다.
Elasticsearch의 Shard와 Node

Elasticsearch 클러스터링 과정
노드를 여러개 실행시키면 이 노드들은 같은 클러스터로 묶여서 같은 시스템으로 동작을 한다.
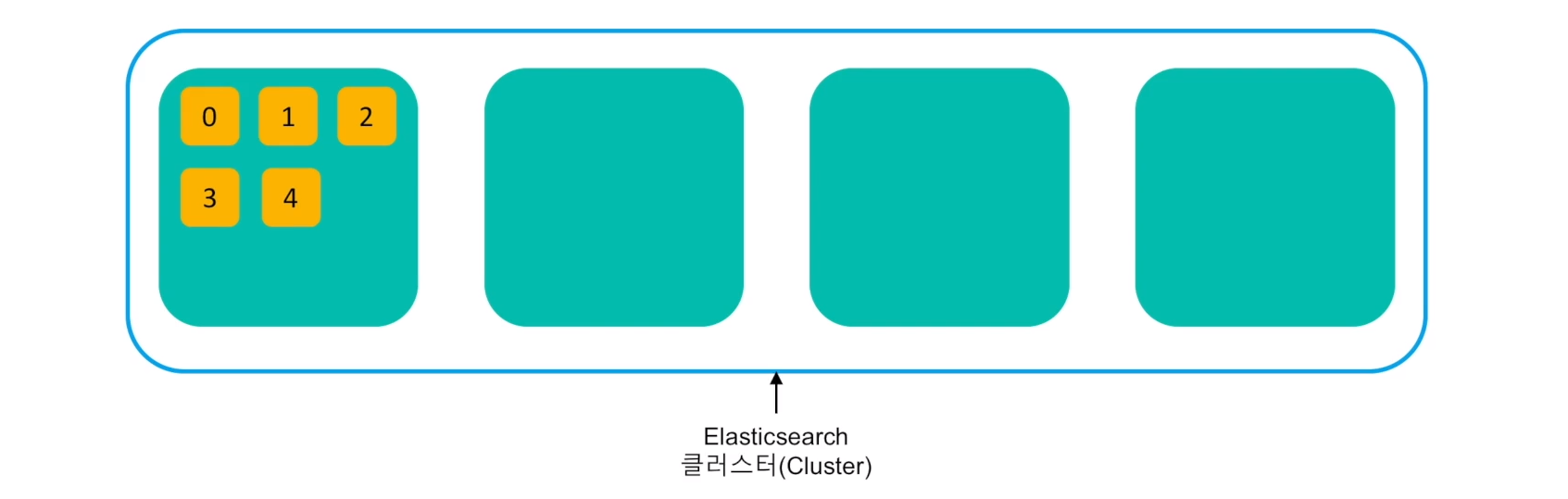
샤드들은 각 노드들의 샤드 레벨로 분배되어 저장된다.
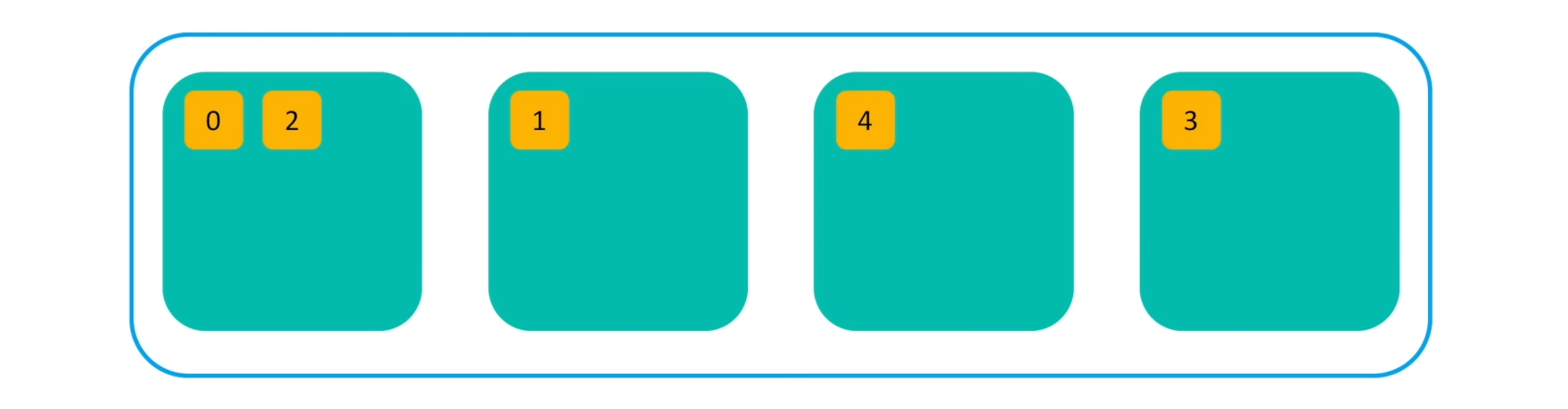
무결성과 가용성을 위해 샤드는 replica라고 하는 복제본을 만들어서 저장 한다. replica의 수는 유동적으로 조절이 가능하며, 항상 Primary 샤드와 Replica는 같은 내용의 Document를 저장하고 있다. 같은 내용을 가지는 Primary와 Replica는 서로 다른 노드에 저장된다.
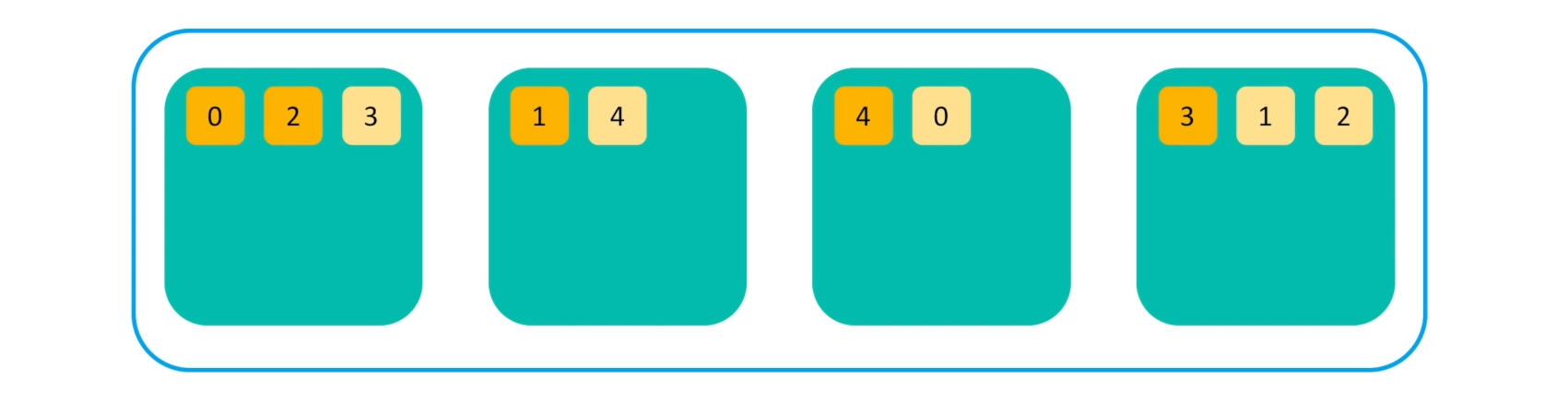
만약, 클러스터내에 있는 한 개 또는 여러 개의 노드가 시스템 다운이나 네트워크 단절 등으로 유실되는 경우에는,

Replica가 없는 샤드들은 다른 살아있는 노드로 Replica를 만들기 시작한다.

결과적으로 노드의 수가 줄어들어도 샤드의 수는 변함 없이 무결성을 유지한다.

Elasticsearch 검색 과정
Query Phase
Client로 부터 검색 명령을 받은 노드가 모든 샤드에게 쿼리를 전달한다. 1차적으로 모든 샤드(Primary 또는 Replica)에서 검색을 실행한다.

각 샤드에서는 클라이언트가 보낸 쿼리에 맞는 해당 도큐먼트를 찾아서, 직접 요청이 들어온 노드로 리턴을 한다. 처음에 리턴하는 결과는 전체 Document가 아닌 Lucene doc id와 해당 Document의 정확도가 가지고 있는 랭킹 점수만 리턴한다.

Fetch Phase
노드는 리턴된 결과들의 랭킹 점수를 기반으로 정렬한 뒤, 실제로 클라이언트로 리턴할 Document를 가지고 있는 샤드들에게만 요청을 한다.

요청을 받은 샤드들은 전체 문서 내용(_source) 등의 정보를 요청 노드로 전달하고, 해당 노드는 클라이언트로 최종 결과를 리턴한다.

위의 과정을 거쳐서 검색이 이루어지기 때문에, 요청과 검색이 서로 다른 노드에서 이루어 지더라도 항상 샤드 레벨로 분배가 되어서 실행된다.
예를 들어, 첫번째 노드에 있는 데이터를 조회하는 검색 요청이 세번째 노드로 가더라도 샤드 레벨로 분배되어 처리된 결과를 세번째 노드가 리턴할 수 있게 된다.
Elasticsearch is...
document-oriented
기본적으로 JSON Document를 사용한다.
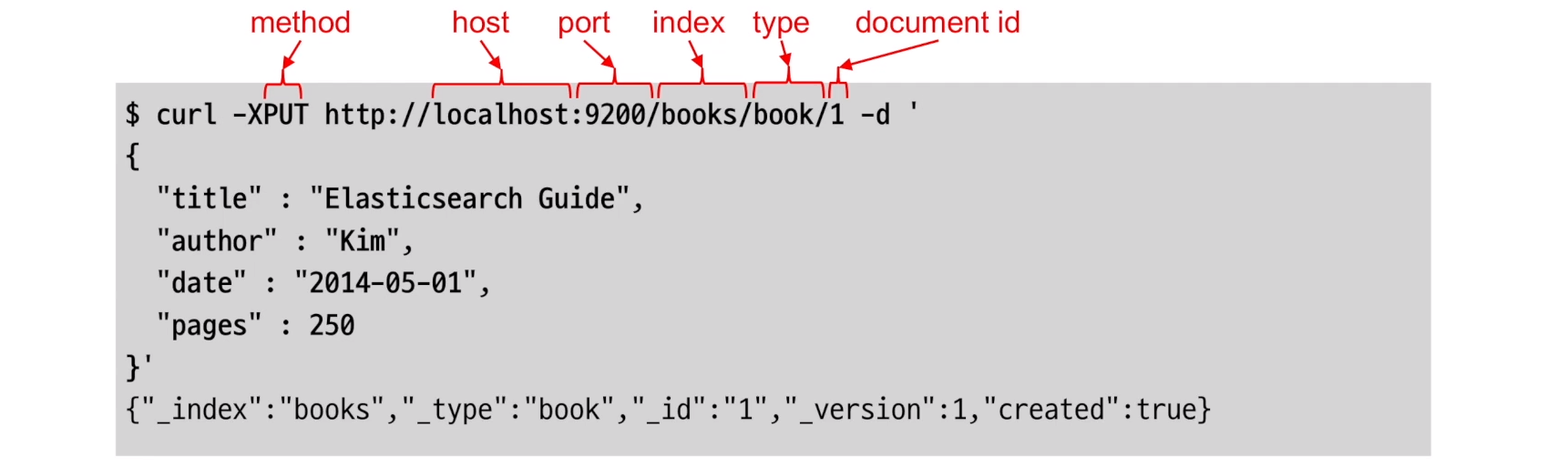
RESTful
REST API를 제공한다.
REST API에서 host, port(기본 9200), index, type, document id 각 레벨을 한 URI로 표현하여 단일 Document를 나타낸다.
동일한 URI는 동일한 Document를 나타내며, 같은 URI로 Document를 UPDATE(PUT) 하게 되면 해당 Document의 내용을 변경할 수 있다.
full text search engine
Elasticsearch는 full text search engine이라는 특성을 가지고 있다.
데이터를 저장할 때, 데이터의 처리 과정을 거치게 된다.
text 문서들을 저장할 때, 검색에 가능한 형태로 가공을 해서 역색인(inverted index) 구조로 저장을 하게 된다.
그렇기 때문에, 검색에 있어서 대소문자 구별이나 원 언어로 검색할 수 있는 기능을 모두 가지고 있다.
real-time search and analytics
Elasticsearch는 실시간 검색 & 분석 시스템이다.
데이터가 저장됨과 동시에 데이터들을 색인 구조로 만들기 때문에, 항상 실시간 검색이나 쿼리질의가 가능하다.
aggregation
검색뿐만 아니라 집계기능을 제공한다.
저장하고 있는 데이터들의 통계분석, 그룹별 통계분석 등의 집계가 가능하기 때문에 검색뿐만 아니라 분석을 위해서도 Elasticsearch를 많이 사용한다.
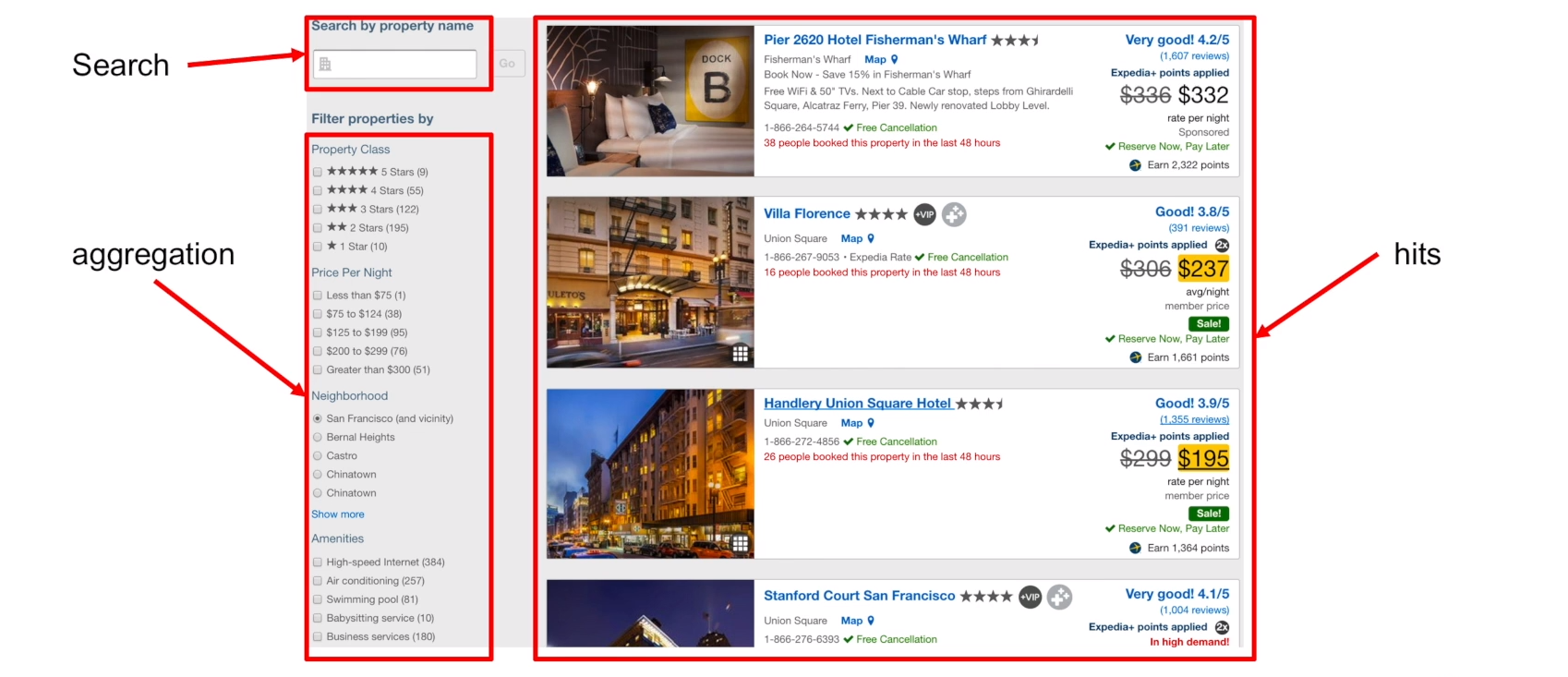
Elasticsearch Demo
Web : www.elastic.co
Products : https://www.elastic.co/products
실행 환경은 CentOS 7.4
설치 및 실행
https://www.elastic.co/kr/downloads/elasticsearch 에서 OS에 맞는 파일을 다운로드 한다.
압축을 풀고 실행한다. 실행하기 전에 Java가 설치 되어 있는지 확인해야 한다.
# java -versionElasticsearch Installation with tar
# curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
# tar -xvf elasticsearch-6.2.3.tar.gz
# cd elasticsearch-6.2.3/bin
# ./elasticsearchElasticsearch installation with RPM
import PGP key
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchcreate RPM repo file
# vi /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdinstall
# sudo yum install elasticsearch
Elasticsearch 실행
현재 사용하는 시스템의 초기화 프로세스가 SysV init인지 systemd 인지 먼저 확인해야 한다. (centos 7 버전은 systemd이며, centos6 이하는 init 프로세스이다.)
# ps -p 1Running Elasticsearch with systemd
바로 elasticsearch 서비스가 올라오지 않고, 올라올때 까지 시간이 조금 걸린다.
# systemctl daemon-reload
# systemctl enable elasticsearch.service
# systemctl start elasticsearch.service
# systemctl stop elaticsearch.service로그에는 elsticsearch.yaml 파일에서 설정한 JVM arguments가 표시되고, 통신을 위해 사용되는 포트들이 표시된다. 기본적으로 9300번 포트를 통해 노드들끼리의 통신이 이루어지고, 9200번 포트를 통해서 client와 통신을 하게 된다.
elasticsearch의 정상적인 실행 여부를, 다음과 같은 명령어를 통해 확인할 수 있다.
명령을 전송하면, elasticsearch의 현재 버전과 클러스터 정보, 노드의 이름 등이 JSON형식으로 리턴 된다.
# curl -XGET localhost:9200실행, 중지, 상태 확인
.service 확장자는 생략가능
# systemctl start elasticsearch
# systemctl stop elasticsearch
# systemctl status elasticsearch
디렉토리 구조
tar로 설치한 경우, 압축이 풀린 폴더로 이동하면, 아래와 같은 파일구조로 구성되어있다.
bin
실행가능한 binary파일들이 위치한다.
linux/unix 환경에서는 elasticsearch 파일을
windows 환경에서는 elasticsearch.bat 파일 또는 .exe을 실행하면 된다.
config
elasticsearch.yml
elasticsearch의 설정에 관련된 파일이다.
cluster명, node명, 데이터가 저장될 data path, log path, network host설정
Network host를 설정하지 않으면, default는 localhost로 설정된다.
elasticsearch의 노드가 localhost로 실행이 되면, 개발자 모드로 실행되서 시작단계에서 bootstrap체크 등을 하지 않는다.
반면에, network host를 설정하게 되면 실제로 clustering을 체크하게 되기 때문에, 시작단계에서 운영환경을 위한 다양한 체크가 들어가게 된다.
elasticsearch는 rest-api를 사용하는 기본적으로 9200번 포트를 사용하여 client와 통신하며, 변경 가능하다.
클러스터링을 위해서 discovery나 unicast설정도 하게 된다. 더 자세한 내용은 documentation에 설명되어있다.
elasticsearch 노드들 사이에서는 zen discovery 프로토콜을 사용한다. zen discovery 프로토콜 설정은 연결해야할 노드들을 배열의 형태로 작성해주면 된다.
discovery.zen.ping.unicast.hosts: ["host1", "host2"]
jvm.options
elasticsearch가 실행할 수 있는 자바 힙 메모리를 설정한다.
Xms와 Xmx를 동일하게 설정 해야 메모리 스왑이 적게 일어난다.
log4j2.properties
elasticsearch에서는 로그를 log4j로 남기기 때문에, 로그를 수정하려면 이 파일을 수정하면 된다.
lib
logs
modules
plugins
RPM으로 설치한 경우 기본 설치 경로
기본 설치 위치($ES_HOME) :
/usr/share/elasticsearch실행파일 :
bin/elasticsearch플러그인 :
plugins
설정 :
/etc/elasticsearchelasticsearch.yml
jvm.options
log4j2.properties
데이터 (path.data) :
/var/lib/elasticsearch로그 (path.logs) :
/var/log/elasticsearch데이터와 로그 파일의 경로는
/etc/elasticsearch/elasticsearch.yml파일에서 수정이 가능하며, 모든 경로에 접근하기 위해서는 기본적으로 root권한을 필요로 한다.
Elasticsearch 클러스터링
김종민 테크 에반젤리스트님의 블로그(클러스터 구성) 포스팅 & 공식 레퍼런스 참조
http://kimjmin.net/2018/01/2018-01-build-es-cluster-1
해당 링크를 참조하면, AWS 기반으로 Elasticsearch 클러스터를 구축하는데 있어서 필요한 세세한 개념까지 설명 되어 있다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
클러스터 아키텍쳐
테스트 클러스터 구축 환경
EC2 - t2.large : 2 vCPU / 8GB
OS - Amazon Linux AMI 2017.09.01
EBS - 10GB
전체 구성은 서비스 노드 1EA, 데이터 노드 3EA
데이터 노드 1 ~ 3 중 임의의 노드 하나가 마스터 노드를 겸하게 되는 구조
NFS(Network File System) 설정을 통해 모든 Data 노드의
/usr/share/elasticsearch디렉토리를 동기화 시키고 업그레이드나 플러그인 설치 등이 한번의 작업으로 가능서비스 노드는 Kibana 및 다른 애플리케이션과의 통신만(REST API 사용 / 9200 port) 처리
서비스 노드와 데이터 노드들은 transport 프로토콜(9300 port)로 통신
데이터 노드들은 REST API를 사용하지 않음
보안그룹 1은 서비스 노드에만 적용 되며, 허가된 포트로만 외부 클라이언트와 통신이 가능
보안그룹 2는 모든 서버에 적용되며, 이 그룹 안의 서버들 끼리는 자유롭게 통신 가능
각 VM에 설치된 X-Pack Security를 통해서 노드간, 클러스터와 사용자 간의 통신을 암호화 하는 SSL/TLS 기능설정
각 VM에 설치된 X-Pack Monitoring을 통해서 ES 클러스터의 VM 상태 모니터링 가능

'ICT Eng > ElasticStack' 카테고리의 다른 글
| [Elasticsearch] API 활용 (0) | 2018.05.14 |
|---|---|
| [Elasticsearch] Relevance - ES의 검색 score 계산 알고리즘(BM25, TF/IDF) (0) | 2018.05.10 |
- Total
- Today
- Yesterday
- Wisoft
- AWS
- IT융합인력양성사업단
- 무선통신소프트웨어연구실
- Vue.js
- Algorithm
- 시간복잡도
- RBT
- 스프링부트
- 인프런
- Spring Boot
- github
- 자바
- 한밭대학교
- springboot
- Spring
- Java
- ORM
- JPA
- vuejs
- 알고리즘
- 레드블랙트리
- 라즈베리파이
- 정렬
- 순환
- vuex
- 젠킨스
- Recursion
- Raspberry Pi
- 한밭이글스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |