
티스토리 뷰
부경대 IT융합응용공학과 권오흠 교수님의 영리한 프로그래밍을 위한 알고리즘 강좌와 '쉽게 배우는 알고리즘: 관계중심의 사고법 - 문병로'등을 통한 알고리즘 학습 강좌 링크
4-2. Binary Search Tree
Dynamic Set
집합이다. 여러개의 데이터의 집합인데, 그것들의 내용이 고정되지 않고, 생성과 삭제를 반복하면서 유동적인 집합이다. 아래와 같은 특징을 가진다. Dynamic Set, Dictionary 또는 Search Structure라고 불린다.
여러 개의 키(key)를 저장
다음과 같은 연산들을 지원하는 자료구조
INSERT - 새로운 키의 삽입
SEARCH - 키 탐색
DELETE - 키의 삭제
예: 심볼 테이블
일반적으로 구현할 때 배열 or 연결리스트를 사용한다.
각 동작에 있어서 다음과 같은 시간복잡도를 가진다.
정렬된 배열의 이진탐색 - O(logn)
정렬된 배열에서 원소를 insert, delete하면 나머지 원소들을 한칸식 shift - O(n)
정렬된 연결리스트의 경우는 이진탐색 불가 - O(n)을 피할 수 없음.
정렬된 연결리스트에서 insert할 자리를 찾는 시간 - O(n)
| 종류 | 정렬 | search | insert | delete |
|---|---|---|---|---|
| 배열 | O | O(logn) | O(n) | O(n)(삭제 후 shift) |
| X | O(n) | O(1) | O(1)(찾았다고 가정하고, 삭제만) | |
| 연결리스트 | O | O(n) | O(n) | O(1)(찾았다고 가정하고, 삭제만) |
| X | O(n) | O(1) | O(1)(찾았다고 가정하고, 삭제만) |
정렬된 혹은 정렬되지 않은 배열, 연결 리스트를 사용할 경우 INSERT, SEARCH, DELETE 중 적어도 하나는 O(n)의 시간복잡도를 가짐.
3가지 연산 모두 O(n)의 시간을 갖지 않는 효율적인 알고리즘은 없는가?
이진탐색트리(Binary Search Tree), 레드-블랙 트리, AVL- 트리등의 트리에 기반한 구조들
Direct Address Table, 해시 테이블 등
검색트리
Dynamic set을 트리의 형태로 구현
일반적으로 SEARCH, INSERT, DELETE 연산이 트리의 높이(height)에 비례하는 시간복잡도를 가진다.
이진검색트리, 레드-블랙트리, B-트리 등
이진검색트리(BST)
이진 트리이면서
각 노드에 하나의 키를 저장
각 노드 v에 대해서 그 노드의 왼쪽 서브트리에 있는 키들은 key[v]보다 작거나 같고, 오른쪽 부트리에 있는 값은 크거나 같다.
SEARCH

pesedo code
키 값에 따라서 왼쪽 서브트리 또는 오른쪽 서브트리를 recursive하게 탐색한다.
시간복잡도: O(h), 여기서 h는 트리의 높이 이다.
Recursive Version
TREE-SEARCH(x, k)
if x = NULL or k = key[x]
then return x
if k < key[x]
then return TREE-SEARCH(left[x], k)
else return TREE-SEARCH(right[x], k)Iterative Version
TREE-SEARCH(x, k)
while x!=NULL and k!=key[x]
do if k < key[x]
then x <- left[x]
else x <- right[x]
return x
최소값 찾기
최소값은 항상 가장 왼쪽 노드에 존재
시간복잡도: O(h)
최대 값은 반대로 가장 오른쪽 노드를 찾아가는 방법으로 찾는다.
TREE-MINIMUM(x)
while left[x] != null
do x <- left[x]
return xSuccessor 찾기
노드 x의 successor란 key[x]보다 크면서 가장 작은 키를 가진 노드
모든 키들이 서로 다르다고 가정한다.
successor의 3가지 경우
노드 x의 오른쪽 서브트리가 존재할 경우, 오른쪽 서브트리의 최소값
오른쪽 서브트리가 없는 경우, 어떤 노드 y의 왼쪽 서브트리의 최대값이 x가 되는 그런 노드 y가 x의 successor
부모를 따라 루트까지 올라가면서 처음으로 왼쪽 링크를 타고 올라간 해당 노드가 y
여기서는 4(x)의 successor를 구할 때, 루트까지 올라가면서 처음으로 왼쪽 링크를 타고 위로 올라간 노드 6(y).
그런 노드 y가 존재하지 않을 경우 successor가 존재하지 않음(즉, x가 최대값)

peudo code
1,2 : 오른쪽 서브트리가 존재할 경우, 오른쪽 트리의 최소 값을 찾는다.
3 : y는 x의 부모노드
4, 5, 6 : 부모노드가 null이 아니고, x가 부모의 오른쪽 자식일 경우에만 계속해서 부모를 찾아 올라간다.
7 : 부모를 찾아 올라가다가 y가 null이거나, 누군가의 왼쪽 자식이 되는 경우 null 또는 y값을return 한다.
시간복잡도 : O(h)
TREE-SUCCESSOR(x)
1 if right[x] != NULL
2 then return TREE-MINIMUM(right[x])
3 y <- p[x]
4 while y != NULL and x = right[y]
5 do x <- y
6 y <- p[y]
7 return y Predecessor
노드 x의 predecessor란 key[x]보다 작으면서 가장 큰 키를 가진 노드
Successor와 반대
INSERT
14의 삽입 위치를 찾으러 13의 오른쪽으로 내려갔는데, x의 위치가 null이 되므로 항상 x의 부모 노드 y를 관리해 준다.

pseudo code
T는 Tree, z는 insert할 노드
1,2 : y = null, x = root노드 에서 출발
3 : x가 null이 아닐때 까지
4 : y에 x를 저장해놓고,
5,6,7 : z와 x의 키값을 비교해서 z의 키값이 x의 키값보다 작으면 왼쪽 노드로, z의 키값이 더 크면 오른쪽 노드로 내려간다. 내려간 뒤, 다시 y에 x를 저장, 반복
8 : 새로운 노드 z의 부모는 y가 된다.
9,10 : y가 NULL이라면, Tree가 NULL이라는 의미이고 z는 root가 된다.
11,12 : z의 키 값이 y보다 작다면 왼쪽 자식이 되고,
13,14 : z의 키 값이 y보다 크다면 오른쪽 자식이 된다.
시간복잡도는 : O(h)
트리의 높이보다 더 많은 시간을 필요로 하진 않는다.
TREE-INSERT(T, z)
01 y <- NULL
02 x <- root[T]
03 while x!= NULL
04 do y <- x
05 if key[z] < key[x]
06 then x <- left[x]
07 else x <- right[x]
08 p[z] <- y
09 if y = NULL
10 then root[T] <- z
11 else if key[z] < key[y]
12 then left[y] <- z
13 else
14 then right[y] <- z
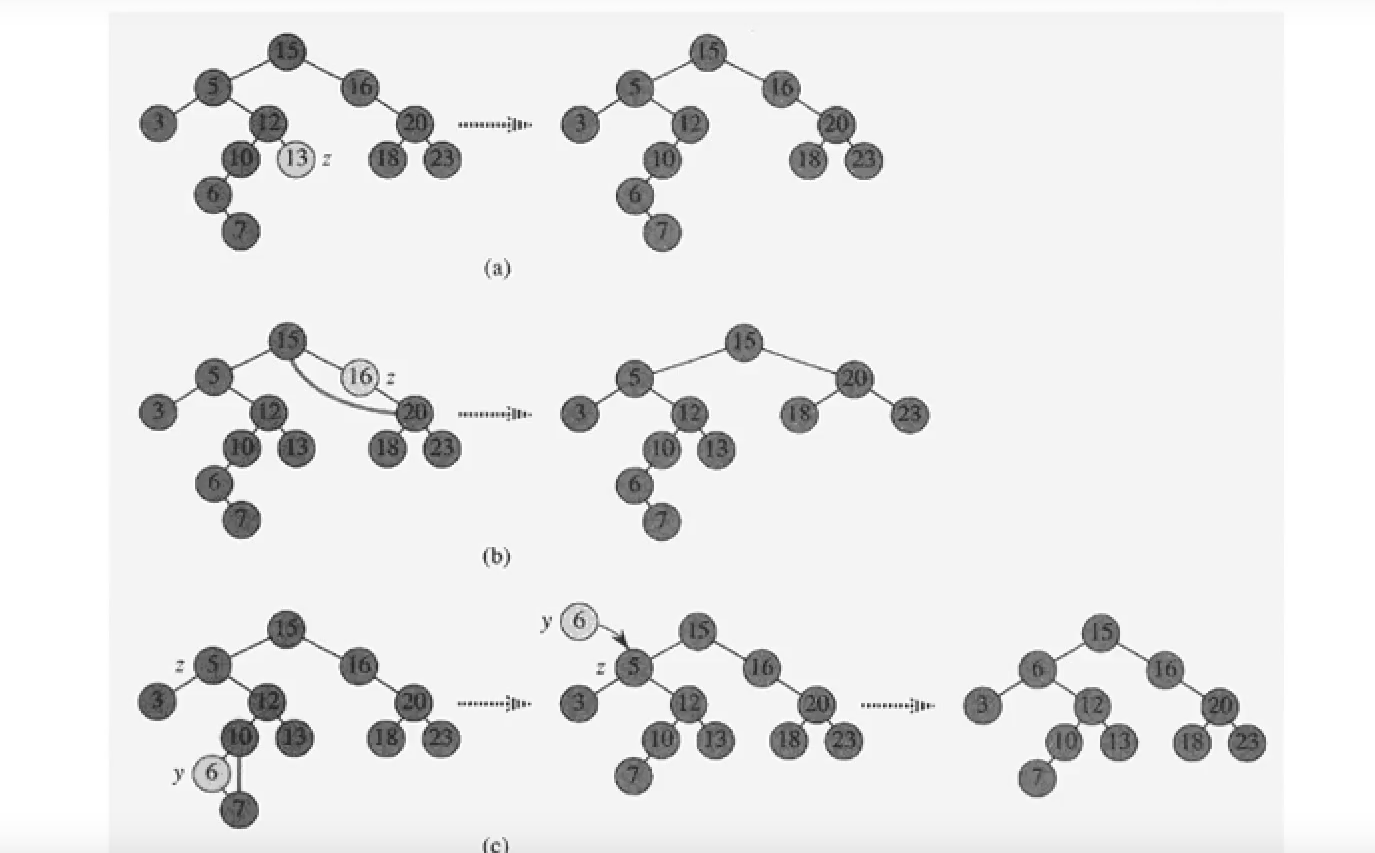
DELETE
Case 1 : 자식노드가 없는 경우
리프노드인경우 그냥 삭제한다.

Case 2 : 자식노드가 1개인 경우
자신의 자식 노드를 원래 자신의 위치가 될 수 있도록 연결한다.

Case 3 : 자식노드가 2개인 경우
가장 복잡한 경우이다. 자식 노드가 2개인 노드를 삭제하는 경우 트리의 구조가 깨지기 때문에 다시 조건을 만족하는 트리를 만들어주는 작업이 필요하다.
13을 삭제하는 경우, 13의 노드에 있는 데이터만 삭제하고,
삭제하려는 노드의 Successor의 데이터만 copy해서 가져온다.
그리고 Successor를 삭제한다.
자식노드가 2개인 노드의 Successor는 왼쪽 자식이 없다는 것이 보장되어 있다. 하지만, 오른쪽 자식은 있을 수도 있고 없을 수도 있다. 즉, 자식노드가 0개 또는 1개이다.
이 경우, Case 1 또는 2에 해당하므로, 방법에 맞게 삭제한다.


Case별 예시
pseudo code
T는 트리 z는 삭제할 노드, 삭제할 노드를 search하는 작업은 이루어 졌다고 가정하고, 삭제하는 로직
1,2,3 : 실제로 트리에서 삭제할 노드 y를 정한다. 자식노드가 0개 또는 1개일 경우 실제로 해당 노드를 삭제할 것이기 때문에 y에 z를 대입한다. 자식노드가 2개일 경우 삭제할 노드 y는 z의 successor를 대입하여 삭제한다.
따라서, 4 - 13라인은 실제 노드 y를 삭제하는 경우이고, 14 - 17라인은 노드 z의 Successor를 삭제하는 case 3인 경우이다.
4, 5, 6 : y의 자식은 0개 또는 1개인 상태이다. y의 왼쪽 자식이 존재한다면, x는 y의 왼쪽 자식이고, 그렇지 않다면 x는 y의 오른쪽 자식이다.
7, 8 : 그리고 x가 NULL이 아니라면, 현재 y의 부모를 x의 부모로 설정한다.
9,10 : y의 부모가 없다면, 즉 y가 루트노드라면, x를 루트로 설정한다.
11,12 : 그렇지 않고 y가 자신의 부모의 왼쪽 자식이었다면, 삭제될 노드 y의 부모의 왼쪽 자식을 x로 설정하고
13 : 그렇지 않고 y가 자신의 부모의 오른쪽 자식이었다면, 삭제될 노드 y의 부모의 오른쪽 자식으로 x를 설정한다. 이렇게 해서 실제 y를 삭제하는 일이 끝났다.
14, 15, 16 : 삭제하려는 노드 z와 실제 트리에서 삭제될 노드 z가 다르다는 것은 case 3에 해당한다는 이야기 이므로, y에 보관되어 있는 데이터를 z의 자리로 옮기고(y의 키값만이 아닌 satellite data들 까지 모두), 실제 삭제된 노드의 데이터 y를 리턴한다.
시간복잡도 O(h)
TREE-DELETE(T, z)
01 if left[z] = NULL or right[z] = null
02 then y <- z
03 else y <- TREE-SUCCESSOR(z)
04 if left[y] != NULL
05 then x <- left[y]
06 else x <- right[y]
07 if x != NULL
08 then p[x] <- p[y]
09 if p[y] = NULL
10 then root[T] <- x
11 else if y = left[p[y]]
12 then left[p[y]] <- x
13 else right[p[y]] <- x
14 if y != z
15 then key[z] <- key[y]
16 copy y's satellite data into z
17 return y
BST 정리
각종 연산의 시간복잡도는 O(h)이다.
최악의 경우 트리의 높이 h는 O(n)이다.
실제 위에서 학습한 BST의 Search, Insert, Delete 모두 최악의 경우 시간복잡도는 O(n)이다.
그러나, 이것은 실제 최악의 경우에 해당한다. BST에 데이터들이 random하게 구성된다고 가정했을때, 평균 트리의 높이는 O(logn)이 된다. 이는 Search, Insert, Delete 연산의 시간복잡도가 O(logn)이 된다는 이야기이다.
최악의 경우에도 O(logn)을 넘지 않도록 하는 균형잡힌 트리
레드-블랙 트리 등
키의 삽입이나 삭제시 추가로 트리의 균형을 잡아줌으로써 높이를 O(logn)으로 유지한다.
'ICT Eng > Algorithm' 카테고리의 다른 글
| [Algorithm] 5-2. Red Black Tree 02 - INSERT, FIXUP 연산 (0) | 2018.03.29 |
|---|---|
| [Algorithm] 5-1. Red Black Tree 01 - 개요 (0) | 2018.03.29 |
| [Algorithm] 4-1. 트리와 이진트리(tree and binary tree) (0) | 2018.02.06 |
| [Algorithm] 알고리즘을 위한 자바 Java IO (1) | 2018.02.06 |
| [Algorithm] 3-9. Sorting in Java (0) | 2018.01.31 |
- Total
- Today
- Yesterday
- Raspberry Pi
- 한밭대학교
- Recursion
- 라즈베리파이
- Spring Boot
- JPA
- Wisoft
- 레드블랙트리
- AWS
- 스프링부트
- 알고리즘
- RBT
- ORM
- vuejs
- 순환
- 정렬
- Spring
- 젠킨스
- springboot
- 한밭이글스
- Java
- IT융합인력양성사업단
- vuex
- github
- Vue.js
- 무선통신소프트웨어연구실
- 인프런
- 자바
- Algorithm
- 시간복잡도
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |