
티스토리 뷰
'이것이 자바다 - 신용권' 16장 학습
1절. 스트림 소개
2절. 스트림의 종류
3절. 스트림 파이프라인
4절. 필터링(distinct(), filter())
5절. 매핑(flatMapXXX(), mapXXX(), asXXXStream(), boxed())
6절. 정렬(sorted())
7절. 루핑(peek(), forEach())
8절. 매칭(allMatch(), anyMatch(), noneMatch())
9절. 기본 집계(sum(), count(), average(), max(), min())
10절. 커스텀 집계(reduce())
11절. 수집(collect())
12절. 병렬 처리
1. 스트림 소개
스트림은 반복자
컬렉션(배열 포함)의 요소를 하나씩 참조해서 람다식으로 처리할 수 있는 반복자이다.
자바 7 이전 코드
List<String> list = Arrays.asList("홍길동", "신용권", "김남준");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String name = iterator.next();
System.out.println(name);
}자바 8 이후 코드
List<String> list = Arrays.asList("홍길동", "신용권", "김남준");
Stream<String> stream = list.stream();
stream.forEach(name -> System.out.println(name));
스트림 특징
람다식으로 요소 처리 코드를 제공한다.
스트림이 제공하는 대부분의 요소 처리 메소드는 함수적 인터페이스 매개타입을 가진다.
매개값으로 람다식 또는 메소드 참조를 대입할 수 있다.
public static void main(String[] args) {
List<Student> list = Array.asList(
new Student("홍길동",92),
new Student("김남준",90)
);
Stream<Student> stream = list.stream();
stream.forEach(s -> {
String name = s.getName();
int score = s.getScore();
System.out.println(name + "-" + score);
});
}
홍길동-92
김남준-90내부 반복자를 사용하므로 병렬 처리가 쉽다.
외부 반복자(external iterator)
개발자가 코드로 직접 컬렉션 요소를 반복해서 요청하고 가져오는 코드 패턴
내부 반복자(internal iterator)
컬렉션 내부에서 요소들을 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 코드 패턴
내부 반복자의 이점
개발자는 요소 처리 코드에만 집중
멀티코어 CPU를 최대한 활용하기 위해 요소들을 분배시켜 병렬 처리 작업을 할 수 있다.
병렬(parallel) 처리
한가지 작업을 서브 작업으로 나누고, 서브 작업들을 분리된 스레드에서 병렬적으로 처리한 후, 서브 작업들의 결과들을 최종 결합하는 방법
자바는 ForkJoinPool 프레임워크를 이용해서 병렬 처리를 한다.
병렬 처리 코드 예
package sec01.stream_introduction;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class ParallelEx {
public static void main(String[] args) {
List<String> list = Arrays.asList("홍길동","신용권","김남준","람다식","병렬처리");
Stream<String> stream = list.stream();
stream.forEach(ParallelEx::print);
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach(ParallelEx::print);
}
public static void print(String string) {
System.out.println(string + " : " + Thread.currentThread().getName());
}
}
홍길동 : main
신용권 : main
김남준 : main
람다식 : main
병렬처리 : main
김남준 : main
병렬처리 : ForkJoinPool.commonPool-worker-2
신용권 : ForkJoinPool.commonPool-worker-1
홍길동 : ForkJoinPool.commonPool-worker-1
람다식 : ForkJoinPool.commonPool-worker-2
Process finished with exit code 0스트림은 중간 처리와 최종 처리를 할 수 있다.
중간 처리: 요소들의 매핑, 필터링, 정렬
최종 처리: 반복, 카운트, 평균, 총합
package sec01.stream_introduction;
import java.util.Arrays;
import java.util.List;
public class MapAndReduceEx {
public static void main(String[] args) {
List<Student> list = Arrays.asList(
new Student("홍길동", 92),
new Student("김남준", 90),
new Student("김자바", 82)
);
double avg = list.stream()
.mapToInt(Student::getScore)
.average()
.getAsDouble();
System.out.println("평균점수: " + avg);
}
}
평균점수: 88.0
Process finished with exit code 0
2. 스트림의 종류
스트림이 포함된 패키지
자바 8 부터 java.util.stream 패키지에서 인터페이스 타입으로 제공
모든 스트림에서 사용할 수 있는 공통 메소드들이 정의 되어있는 BaseStream아래에 객체와 타입 요소를 처리하는 스트림이 있다. BaseStream은 공통 메소드들이 정의되어 있고, 코드에서 직접적으로 사용하지는 않는다.
BaseStream
Stream
IntStream
LongStream
DoubleStream
스트림 구현 객체를 얻는 방법
| 리턴타입 | 메소드(매개변수) | 소스 |
|---|---|---|
| Stream<T> | java.util.Collection.stream(), java.util.Collection.parallelStream() | 컬렉션 |
| Stream<T>, IntStream, LongStream, DoubleStream | Arrays.stream(T[]), Arrays.stream(int[]), Arrays.stream(long[]), Arrays.stream(double[]), Stream.of(T[]), IntStream.of(int[]), LongStream.of(long[]), DoubleStream.of(double[]) | 배열 |
| IntStream | IntStream.range(int, int), IntStream.rangeClosed(int, int) | Int 범위. rangeClosed() 메소드는 두번째 파라미터인 끝값을 포함한다. range()는 포함하지 않는다. |
| LongStream | LongStream.range(long, long), LongStream.rangeClosed(long, long) | long 범위. rangeClosed() 메소드는 두번째 파라미터인 끝값을 포함한다. range()는 포함하지 않는다. |
| Stream<Path> | Files.find(Path, int, BiPredicate, FileVisitOption), Files.list(Path) | 디렉토리 - Path 경로에서 BiPredicate가 true인 Path Stream을 얻을 수 있다. |
| Stream<String> | Files.lines(Path, Charset), BufferedReader.lines() | 파일 - 한 라인에 대한 텍스트 정보를 요소가지는 Stream을 얻을 수 있다. |
| DoubleStream, IntStream, LongStream | Random.doubles(…), Random.ints(), Random.longs() | 랜덤수 |
컬렉션으로부터 스트림 얻기
List<Student> studentList = Arrays.asList(
new Student("홍길동", 10),
new Student("김길동", 20),
new Student("남길동", 30)
);
Stream<Student> stream = studentList.stream();
stream.forEach(s -> System.out.println(s.getName()));
홍길동
김길동
남길동
배열로부터 스트림 얻기
String[] stringArray = {"홍길동", "신용권", "김미나"};
Stream<String> stringStream = Arrays.stream(stringArray);
stringStream.forEach(a -> System.out.print(a + ","));
System.out.println();
int[] intArray = {1, 2, 3, 4, 5};
IntStream intStream = Arrays.stream(intArray);
intStream.forEach(a -> System.out.print(a + ","));
홍길동,신용권,김미나,
1,2,3,4,5,
숫자 범위로부터 스트림 얻기
public class FromIntRangeEx {
public static int sum;
public static void main(String[] args) {
IntStream stream = IntStream.rangeClosed(1, 100);
//IntStream stream = IntStream.range(1, 100); //범위에 100이 포함되지 않음
stream.forEach(a -> sum += a);
System.out.println("총합: " + sum);
}
}
총합: 5050
또는
총합: 4950
파일로부터 스트림 얻기
Path path = Paths.get("/Users/njkim/Workspace/intellij/this_is_java/ch16_스트림과병렬처리/src/sec02/kind_of_stream/linedata.txt");
Stream<String> stream;
stream = Files.lines(path, Charset.defaultCharset());
stream.forEach(System.out::println);
stream.close();
System.out.println();
File file = path.toFile();
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
stream = bufferedReader.lines();
stream.forEach(System.out::println);
stream.close();
Java8에서 추가된 새로운 기능
1. 람다식
2. 메소드 참조
3. 디폴트 메소드와 정적 메소드
4. 새로운 API 패키지
Java8에서 추가된 새로운 기능
1. 람다식
2. 메소드 참조
3. 디폴트 메소드와 정적 메소드
4. 새로운 API 패키지
디렉토리로부터 스트림 얻기
Path path = Paths.get("/Users/njkim/Workspace/intellij/this_is_java");
Stream<Path> stream = Files.list(path);
stream.forEach(p -> System.out.println(p.getFileName()));
ch14_람다식
ch08_인터페이스
ch15_컬렉션프레임워크
.DS_Store
out
ch07_상속
ch02_변수와타입
ch04_조건문과반복문
ch06_클래스
ch12_멀티스레드
ch03_연산자
README.md
ch05_참조타입
.gitignore
ch10_예외처리
ch16_스트림과병렬처리
ch09_중첩클래스와_중첩인터페이스
ch13_제네릭
ch11_기본_API_클래스
.git
.idea
3. 스트림 파이프라인
중간 처리와 최종 처리
리덕션(Reduction)
대량의 데이터를 가공해서 축소하는 것을 말한다.
합계, 평균값, 카운팅, 최대값, 최소값등을 집계하는 것
요소가 리덕션의 결과물로 바로 집계할 수 없을 경우 중간 처리가 필요하다.
중간 처리 : 필터링, 매핑, 정렬, 그룹핑
중간 처리한 요소를 최종 처리해서 리덕션 결과물을 산출한다.
스트림은 중간 처리와 최종 처리를 파이프라인으로 해결한다.
파이프라인(pipelines): 스트림을 파이프처럼 이어 놓은 것을 말한다.
중산처리 메소드(필터링, 매핑, 정렬)는 중간 처리된 스트림을 리턴하고,
이 스트림에서 다시 중간 처리 메소드를 호출해서 파이프라인을 형성하게 된다.
최종 스트림의 집계 기능이 시작되기 전까지 중간 처리는 지연(lazy)된다.
최종 스트림이 시작하면 비로소 컬렉션에서 요소가 하나씩 중간 스트림에서 처리되고 최종 스트림까지 오게된다.
예) 회원 컬렉션에서 남자 회원의 평균 나이
Stream<Member> maleFemaleStream = list.stream();
Stream<Member> maleStream = maleFemaleStream.filter(m -> m.getSex() == Member.MALE);
IntStream ageStream = maleStream.mapToInt(Member::getAge);
OptionalDouble optionalDouble = ageStream.average();
double ageAvg = optionalDouble.getAsDouble();
double ageAvg = list.stream() //오리지날 스트림
.filter(m -> m.getSex() == Member.MALE) //중간 처리 스트림
.mapToInt(Member::getAge) //중간 처리 스트림
.average() //최종 처리
.getAsDouble();예제 코드
package sec03.stream_pipelines;
import java.util.Arrays;
import java.util.List;
public class StreamPipelinesEx {
public static void main(String[] args) {
List<Member> list = Arrays.asList(
new Member("홍길동", Member.MALE, 30),
new Member("김나리", Member.FEMALE, 20),
new Member("김남준", Member.MALE, 25),
new Member("박수미", Member.FEMALE, 28)
);
double avg = list.stream()
.filter(m -> m.getSex() == Member.MALE)
.mapToInt(Member::getAge)
.average()
.getAsDouble();
System.out.println(avg);
}
}
남자 평균 나이: 27.5
Process finished with exit code 0
중간 처리 메소드롸 최종 처리 메소드
리턴 타입을 보면 중간 처리 메소드인지 최종 처리 메소드인지 구분할 수 있다.
중간 처리 메소드 : 리턴 타입이 스트림
최종 처리 메소드 : 리턴 타입이 기본 타입이거나 OptionalXXX
중간 처리 메소드
중간 처리 메소드는 최종 처리 메소드가 실행되기 전까지 지연한다.
최종 처리 메소드가 실행이 되어야만 동작을 한다.

최종 처리 메소드

4. 필터링 중간 처리 - distinct(), filter()
중간 처리 기능으로 요소를 걸러내는 역할을 한다.

distinct()
중복을 제거하는 스트림 필터링 메소드
Stream: equals() 메소드가 true가 나오면 동일한 객체로 판단하고 중복을 제거
IntStream, LongStream, DoubleStream: 동일값일 경우 중복을 제거
filter()
매개값으로 주어진 Predicate가 true를 리턴하는 요소만 필터링한다.
distinct(), filter() 실습 예제
distinct()로 List에 저장된 중복 객체를 제거하고,
filter()를 통해서 조건에 맞는 객체만을 찾아서
forEach()를 통해 하나씩 출력한다.
package sec04.stream_filtering;
import java.util.Arrays;
import java.util.List;
public class FilteringEx {
public static void main(String[] args) {
List<String> names = Arrays.asList("홍길동", "신용권", "김자바", "신용권", "김남준", "김남준");
names.stream()
.distinct()
.forEach(System.out::println);
System.out.println();
names.stream()
.filter(str -> str.startsWith("신"))
.forEach(System.out::println);
System.out.println();
names.stream()
.distinct()
.filter(str -> str.endsWith("준"))
.forEach(System.out::println);
}
}
홍길동
신용권
김자바
김남준
신용권
신용권
김남준
Process finished with exit code 0
5. 매핑 중간 처리 - flatMapXXX(), mapXXX(), asXXXStream(), box
매핑(mapping)은 중간 처리 기능으로 스트림의 요소를 다른 요소로 대체 한다.
예를 들면, 객체를 정수로, 객체를 double로, 객체를 boolean값으로 대체하는 것을 말한다. 반드시 하나의 요소가 하나의 요소로 대체 되는것은 아니다. 하나의 요소가 여러개의 요소로 대체될 수도 있다.
매핑 메소드 종류
flatMapXXX(), mapXXX(), asDoubleStream(), asLongStream(), boxed()
flatMapXXX()메소드
한 개의 요소를 대체하는 복수개의 요소들로 구성된 새로운 스트림을 리턴한다.
| 리턴타입 | 메소드(매개변수) | 요소 -> 대체 요소 |
|---|---|---|
| Stream<R> | flatMap(Function<T, Stream<R>>) | T -> Stream<R> |
| DoubleStream | flatMap(DoubleFunction<DoubleStream>) | double -> DoubleStream |
| IntStream | flatMap(IntFunction<IntStream>) | int -> IntStream |
| LongStream | flatMap(LongFunction<LongStream>) | long -> longStream |
| DoubleStream | flatMapToDouble(Function<T, DoubleStream>) | T -> DoubleStream |
| IntStream | flatMapToInt(Function<T, IntStream>) | T -> IntStream |
| LongStream | flatMapToLong(Function<T, LongStream>) | T -> LingStream |
flatMapXXX() 실습 예제
다음 예제는 입력된 데이터(요소)들이 List<String>에 저장되어 있다고 가정하고, 요소별로 단어를 뽑아 단어 스트림으로 재생성한다. 만약 입력된 데이터들이 숫자라면 숫자를 뽑아 숫자 스트림으로 재생성한다.
package sec05.stream_mapping;
import java.util.Arrays;
import java.util.List;
public class FlatMapEx {
public static void main(String[] args) {
List<String> inputList1 = Arrays.asList("java8 lambda", "stream mapping");
inputList1.stream()
.flatMap(data -> Arrays.stream(data.split(" ")))
.forEach(System.out::println);
System.out.println();
List<String> inputList2 = Arrays.asList("10, 20, 30", "40, 50, 60");
inputList2.stream()
.flatMapToInt(data -> {
String[] strArray = data.split(",");
int[] intArray = new int[strArray.length];
for (int i = 0; i < strArray.length; i++) {
intArray[i] = Integer.parseInt(strArray[i].trim());
}
return Arrays.stream(intArray);
})
.forEach(System.out::println);
}
}
java8
lambda
stream
mapping
10
20
30
40
50
60
Process finished with exit code 0
mapXXX() 메소드
요소를 대체하는 요소로 구성된 새로운 스트림을 리턴한다.
flatMapXXX() 메소드는 하나의 요소를 여러개의 요소로 대체 하고, mapXXX() 메소드는 하나의 요소로 대체 한다.

mapXXX() 실습 예제
package sec05.stream_mapping;
import java.util.Arrays;
import java.util.List;
public class MapEx {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student("홍길동", 10),
new Student("신용권", 20),
new Student("김남준", 30)
);
studentList.stream()
.mapToInt(Student::getScore)
.forEach(System.out::println);
}
}
10
20
30
Process finished with exit code 0
asDoubleStream(), asLongStream(), boxed() 메소드
| 리턴타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| DoubleStream | asDoubleStream() | int -> double, long -> double |
| LongStream | asLongStream() | int -> long |
| Stream<Integer>, Stream<Long>, Stream<Double> | boxed() | int -> Integer, long -> Long, double -> Double |
asDoubleStream()
IntStream()의 int요소 또는 LongStream의 long요소를 double요소로 타입 변환해서 DoubleStream을 생서
asLongStream()
IntStream()의 int요소를 long요소로 타입 변환해서 LongStream을 생성
boxed()
int요소, long요소, double요소를 Integer, Long, Double요소로 박싱해서 Stream을 생성
asDoubleStream, boxed() 실습 예제
package sec05.stream_mapping;
import java.util.Arrays;
import java.util.stream.IntStream;
public class AsDoubleStreamAndBoxedEx {
public static void main(String[] args) {
int[] intArray = {1, 2, 3, 4, 5};
IntStream intStream = Arrays.stream(intArray);
intStream.asDoubleStream().forEach(System.out::println);
System.out.println();
intStream = Arrays.stream(intArray);
intStream.boxed().forEach(System.out::println);
}
}
1.0
2.0
3.0
4.0
5.0
1
2
3
4
5
Process finished with exit code 0
6. 정렬 중간 처리 - sorted()
중간 처리 기능으로 최종 처리되기 전에 요소를 정렬한다.
| 리턴타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| Stream<T> | sorted() | 객체를 Comarable 구현 방법에 따라 정렬 |
| Stream<T> | sorted(Comparator<T>) | 객체를 주어진 Comparator에 따라 정렬 |
| DoubleStream | sorted() | double 요소를 올림 차순으로 정렬 |
| IntStream | sorted() | int 요소를 올림 차순으로 정렬 |
| LongStream | sorted() | long 요소를 올림 차순으로 정렬 |
객체 요소일 경우에는 Comparable을 구현하지 않으면 첫번째 sorted() 메소드를 호출하면 ClassCastException이 발생
객체 요소가 Compatable을 구현하지 않았거나, 구현 했다하더라도 다른 비교 방법으로 정렬하려면 Comparator를 매개값으로 갖는 두번째 sorted() 메소드를 사용해야 한다.
Comparator는 함수적 인터페이스이므로 다음과 같이 람다식으로 매개값을 작성할 수 있다.
sorted((a, b) -? { ... })중괄호 {} 안에는 a와 b를 비교해서 a가 작으면 음수, 같으면 0, a가 크면 양수를 리턴하는 코드를 작성
정렬 코드 예
객체 요소가 Comparable을 구현하고 있고, 기본 비교(Comparable) 방법으로 정렬
다음 세가지 방법 중 하나를 선택
sorted();
sorted((a, b) -> a.compareTo(b));
sorted(Comparator.naturalOrder());요소가 Comparable을 구현하고 있지만, 기본 비교 방법과 정반대 방법으로 정렬
위에서의 정렬 방법과 정반대의 결과가 나온다.
sorted((a, b) -> b.compareTo(a));
sorted(Comparator.reverseOrder());
정렬 실습 예제
sorted() 메소드를 이용하여 스트림 중간 처리를 한다. Comparator.reverseOrder()를 통해 정반대의 정렬을 할 수 있다.
package sec06.stream_sorting;
public class Student implements Comparable<Student> {
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public int compareTo(Student o) {
return Integer.compare(score, o.score);
}
}
package sec06.stream_sorting;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.stream.IntStream;
public class SortingEx {
public static void main(String[] args) {
IntStream intStream = Arrays.stream(new int[]{5, 3, 2, 1, 4,});
intStream.sorted().forEach(n -> System.out.print(n + ","));
System.out.println();
List<Student> studentList = Arrays.asList(
new Student("홍길동", 30),
new Student("신용권", 33),
new Student("김남준", 25)
);
studentList.stream()
.sorted()
.forEach(student -> System.out.print(student.getScore() + ","));
System.out.println();
studentList.stream()
.sorted(Comparator.reverseOrder())
.forEach(student -> System.out.print(student.getScore() + ","));
}
}
1,2,3,4,5,
25,30,33,
33,30,25,
Process finished with exit code 0
7. 루핑(looping)
중간 또는 최종 처리 기능으로 요소 전체를 반복하는 것을 말한다.
루핑 메소드
peek() : 중간 처리 메소드
최종 처리 메소드가 실행되지 않으면 지연되기 때문에 최종 처리 메소드가 호출되어야만 동작한다.
루핑 미동작
intStream
.filter(a -> a % 2 == 0)
.peek(System.out::println);루핑 동작
intStream
.filter(a -> a % 2 == 0)
.peek(System.out::println)
.sum()
forEach() : 최종 처리 메소드
intStream
.filter(a -> a % 2 == 0)
.forEach(System.out::println);
루핑 실습 예제
package sec07.stream_looping;
import java.util.Arrays;
public class LoopingEx {
public static void main(String[] args) {
int[] intArr = {1, 2, 3, 4, 5};
System.out.println("[peek()를 마지막에 호출한 경우]");
Arrays.stream(intArr)
.filter(a -> a % 2 == 0)
.peek(System.out::println); //동작하지 않는다.
System.out.println();
System.out.println("[최종 처리 메소드를 마지막에 호출한 경우]");
int sum = Arrays.stream(intArr)
.filter(a -> a % 2 == 0)
.peek(System.out::println)
.sum();
System.out.println("총합: " + sum);
System.out.println("[forEach()를 마지막에 호출한 경우]");
Arrays.stream(intArr)
.filter(a -> a % 2 == 0)
.forEach(System.out::println);
}
}
[peek()를 마지막에 호출한 경우]
[최종 처리 메소드를 마지막에 호출한 경우]
2
4
총합: 6
[forEach()를 마지막에 호출한 경우]
2
4
Process finished with exit code 0
8. 매칭(matching) 최종 처리
최종 처리 기능으로 요소들이 특정 조건을 만족하는지 조사하는 것을 말한다.
매칭 메소드
allMatch()
모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
anyMatch()
최소한 한 개의 요소가 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
noneMatch()
모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하지 않는지 조사

매칭 실습 예제
package sec08.stream_match;
import java.util.Arrays;
public class MatchEx {
public static void main(String[] args) {
int[] intArray = {2, 4, 6};
boolean result = Arrays.stream(intArray).allMatch(a -> a % 2 == 0);
System.out.println("모두 2의 배수인가? " + result);
result = Arrays.stream(intArray).anyMatch(a -> a % 3 == 0);
System.out.println("3의 배수가 있는가? " + result);
result = Arrays.stream(intArray).noneMatch(a -> a % 3 == 0);
System.out.println("3의 배수가 없는가? " + result);
}
}
모두 2의 배수인가? true
3의 배수가 있는가? true
3의 배수가 없는가? false
Process finished with exit code 0
9. 기본 집계 최종 처리
집계(Aggregate)
최종 처리 기능
카운팅, 합계, 평균값, 최대값, 최소값등과 같이 하나의 값으로 산출한다.
대량의 데이터를 가공해서 축소하는 리덕션(Reduction)이라고 볼 수 있다.
스트림이 제공하는 기본 집계 함수
| 리턴타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| long | count() | 요소 개수 |
| OptionalXXX | findFirst() | 첫번째 요소 |
| Optional<T> | max(Compatator<T>) | 최대 요소 |
| OptionalXXX | max() | 최대 요소 |
| Optional<T> | min(Comparator<T>) | 최소 요소 |
| OptionalXXX | min() | 최소 요소 |
| OptionalDouble | average() | 요소 평균 |
| int, long, double | sum() | 요소 총합 |
OptionalXXX 클래스
자바8부터 추가된 값을 저장하는 값 기반 클래스
java.util 패키지의 Optional, OptionalDouble, OptionalInt, OptionalLong 클래스를 말한다.
저장괸 값을 얻으려면 get(), getAsDouble(), getAsInt(), getAsLong() 메소드를 호출한다.
Aggregate 실습 예제
package sec09.stream_aggregate;
import java.util.Arrays;
public class AggregateEx {
public static void main(String[] args) {
long count = Arrays.stream(new int[]{1, 2, 3, 4, 5})
.filter(n -> n % 2 == 0)
.count();
System.out.println("2의 배수의 수: " + count);
long sum = Arrays.stream(new int[]{1, 2, 3, 4, 5})
.filter(n -> n % 2 == 0)
.sum();
System.out.println("2의 배수의 합: " + sum);
int max = Arrays.stream(new int[]{1, 2, 3, 4, 5})
.filter(n -> n % 2 == 0)
.max()
.getAsInt();
System.out.println("2의 배수 중 최대값: " + max);
int min = Arrays.stream(new int[]{1, 2, 3, 4, 5})
.filter(n -> n % 2 == 0)
.min()
.getAsInt();
System.out.println("2의 배수 중 최소값: " + min);
int first = Arrays.stream(new int[]{1, 2, 3, 4, 5})
.filter(n -> n % 3 == 0)
.findFirst()
.getAsInt();
System.out.println("첫번째 3의 배수: " + first);
}
}
2의 배수의 수: 2
2의 배수의 합: 6
2의 배수 중 최대값: 4
2의 배수 중 최소값: 2
첫번째 3의 배수: 3
Process finished with exit code 0
Optional 클래스
값을 저장하는 값 기반 클래스
Optional, OptionalDouble, OptionalInt, OptionalLong
집계 메소드의 리턴 타입으로 사용되어 집계 값을 가지고 있늠
특징
집계 값이 존재하지 않을 경우 디폴트 값을 설정할 수도 있다.
집계 값을 처리하는 Consumer를 등록할 수 있다.
| 리턴타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| boolesn | isPresent() | 값이 저장되어 있는지 여부 |
| T | orElse(T) | 값이 저장되어 있지 않을 경우 디폴트 값 |
| double | orElse(double) | 값이 저장되어 있지 않을 경우 디폴트 값 |
| int | orElse(int) | 값이 저장되어 있지 않을 경우 디폴트 값 |
| long | orElse(long) | 값이 저장되어 있지 않을 경우 디폴트 값 |
| void | ifPresent(Consumer) | 값이 저장되어 있을 경우 Consumer에서 처리 |
| void | ifPresent(DoubleConsumer) | 값이 저장되어 있을 경우 Consumer에서 처리 |
| void | ifPresent(IntConsumer) | 값이 저장되어 있을 경우 Consumer에서 처리 |
| void | ifPresent(LongConsumer) | 값이 저장되어 있을 경우 Consumer에서 처리 |
Optional 실습 예제
package sec09.stream_aggregate;
import java.util.ArrayList;
import java.util.List;
import java.util.OptionalDouble;
public class OptionalEx {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
OptionalDouble optional = list.stream()
.mapToInt(Integer::intValue)
.average();
if(optional.isPresent()) {
System.out.println("방법1 평균: " + optional.getAsDouble());
} else {
System.out.println("방법1 평균: 0.0");
}
double avg = list.stream()
.mapToInt(Integer::intValue)
.average()
.orElse(0.0);
System.out.println("orElse를 이용한 평균: " + avg);
list.add(2);
list.add(4);
list.stream()
.mapToInt(Integer::intValue)
.average()
.ifPresent(a -> System.out.println("isPresent를 이용한 평균: " + a));
}
}
방법1 평균: 0.0
orElse를 이용한 평균: 0.0
isPresent를 이용한 평균: 3.0
Process finished with exit code 0
커스텀 집계 - reduce()
reduce() 메소드
프로그램화해서 다양한 집계(리덕션) 결과물을 만들수 있다.
Stream 인터페이스 타입의 두 메소드를 보면
첫번째 메소드는 BinaryOperator를 매개 변수로 받으므로 두 값의 연산 결과를 Optional하게 리턴한다는 의미이고
두번째 메소드는 두 값의 연산결과를 리턴하되, 결과가 없다면(연산이 안되는 경우 즉, 두개의 요소가 없는 예외 발생 경우 NoSuchElementException) default로 identity값을 리턴한다는 의미이다.
| 인터페이스 | 리턴타입 | 메소드(매개변수) |
|---|---|---|
| Stream | Optional<T> | reduce(BinaryOperator<T> accumulator) |
| Stream | T | reduce(T identity, BinaryOperator<T> accumulator) |
| IntStream | OptionalInt | reduce(IntBinaryOperator op) |
| IntStream | int | reduce(int identity, IntBinaryOperator op) |
| LongStream | OptionalLong | reduce(LongBinaryOperator op) |
| LongStream | long | reduce(long identity, LongBinaryOperator op) |
| DoubleStream | OptionalDouble | reduce(DoubleBinaryOperator op) |
| DoubleStream | double | reduce(double identity, DoubleBinaryOperator op) |
매개변수
XXXBinaryOperator : 두 개의 매개값을 받아 연산 후 리턴하는 함수적 인터페이스
identity : 스트림에 요소가 전혀 없을 경우 리턴될 디폴트 값
예: 학생들의 성적 총점
int sum = studentList.stream()
.map(Student::getScore)
.reduce((a, b) -> a + b)
.get();
int sum = studentList.stream()
.map(Student::getScore)
.reduce(0, (a, b) -> a + b)reduce() 실습 예제
package sec10.stream_reduce;
import java.util.Arrays;
import java.util.List;
public class ReductionEx {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student("홍길동", 90),
new Student("신용권", 70),
new Student("김남준", 98)
);
int sum1 = studentList.stream()
.mapToInt(Student::getScore)
.sum();
int sum2 = studentList.stream()
.mapToInt(Student::getScore)
.reduce((a, b) -> a + b)
.getAsInt();
int sum3 = studentList.stream()
.mapToInt(Student::getScore)
.reduce(0, (a, b) -> a + b);
System.out.println("sum1: " + sum1);
System.out.println("sum2: " + sum2);
System.out.println("sum3: " + sum3);
}
}
sum1: 258
sum2: 258
sum3: 258
Process finished with exit code 0
11. 수집 최종 처리 - collect()
collect()
최종 처리 기능으로 요소들을 수집 또는 그룹핑한다.
필터링 또는 매핑된 요소들로 구성된 새로운 컬렉션을 생성한다.
요소들을 그룹핑하고, 집계(리덕션)을 할 수 있다.
예를 들면, 전체 학생 요소들 중에서 남학생과 여학생을 따로 그룹핑하여 집계할 수 있다.
필터링한 요소 수집
| 리턴타입 | 메소드(매개변수) | 인터페이스 |
|---|---|---|
| R | collect(Collector<T, A, R> collector) | Stream |
Collector의 타입 파라미터
T : 요소
A : 누적기(accumulator)
R : 요소가 저장될 새로운 컬렉션
==> T요소를 A누적기가 R에 저장한다.
Collector의 구현 객체
Collectors 클래스의 정적 메소드를 이용
A(누적기)가 ?인 이유
List, Set, Map 컬렉션에 누적할 경우에는 이미 Collector에서 어느 컬렉션에 저장하는지 알기 때문에 별도의 A(누적기)가 필요 없다.
리턴타입 메소드 설명 Collector<T, ?, Collection<T>> Collectors.toCollection(Supplier<T>) Supplier가 제공한 Collection에 저장 Collector<T, ?, ConcurrentMap<K, U>> Collectors.toConcurrentMap(...) ConcurrentMap에 저장 Collector<T, ?, List<T>> Collectors.toList() List에 저장 Collector<T, ?, Map<K, U>> Collectors.toMap(...) Map에 저장 Collector<T, ?, Set<T>> Collectors.toSet() Set에 저장 전체 학생 List에서 남학생들만 별도의 List로 생성
List<Student> maleList = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(Collectors.toList());전체 학생 List에서 여학생들만 별도의 HashSet으로 생성
HashSet 객체를 Supplier가 생성하도록 했다.
Collectors.toSet()을 이용해도 상관없다.
Set<Student> femaleSet = totalList.stream()
.filter(s -> s.getSet() == Student.Set.FEMALE)
.collect(Collectors.toCollection(HashSet::new));collect() 실습 예제
package sec11.stream_collect;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class ToListEx {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(
new Student("홍길동", 10, Student.Sex.MALE),
new Student("홍길순", 12, Student.Sex.FEMALE),
new Student("김남", 10, Student.Sex.MALE),
new Student("김여", 8, Student.Sex.FEMALE)
);
List<Student> maleList = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(Collectors.toList());
maleList.forEach(s -> System.out.println(s.getName()));
Set<Student> femaleSet = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.FEMALE)
.collect(Collectors.toCollection(HashSet::new));
femaleSet.forEach(s -> System.out.println(s.getName()));
}
}
홍길동
김남
김여
홍길순
Process finished with exit code 0
사용자 정의 컨테이너에 수집하기
List, Set, Map에 수집하는 것이 아니라 사용자 정의 컨테이너에 수집시키는 것을 말한다. 즉, 사용자거 정의한 클래스.
인터페이스 리턴타입 메소드(매개변수) Stream R collect(Supplier<R>, BiConsumer<R, ?, super T>, BiConsumer<R, R>) IntStream R collect(Supplier<R>, ObjIntConsumer<R>, BiConsumer<R, R>) LongStream R collect(Supplier<R>, ObjLongConsumer<R>, BiConsumer<R, R>) DoubleStream R collect(Supplier<R>, ObjDoubleConsumer<R>, BiConsumer<R, R>) 매개변수
첫번째 Supplier - 요소들이 수집될 컨테이너 객체를 생성하는 역할
순차 처리(싱글 스레드) 스트림: 단 한 번 Supplier가 실행
병렬 처리(멀티 스레드) 스트림: 스레드별로 Supplier가 실행되어 스레드별로 컨테이너가 생성
두번째 XXXConsumer - 컨테이너 객체에 요소를 수집하는 역할
스트림에서 요소를 컨테이너에 누적할 때마다 실행
세번째 BiConsumer: 컨테이너 객체를 결합하는 역할
순차 처리(싱글 스레드) 스트림: 실행되지 않음
병렬 처리(멀티 스레드) 스트림: 스레드별로 생성된 컨테이너를 결합해서 최종 컨테이너를 완성한다.
리턴타입
R - 최종 누적된 컨테이너 객체
사용자 정의 컨테이너 수집 예제
package sec11.stream_collect;
import java.util.ArrayList;
import java.util.List;
public class MaleStudent {
private List<Student> list;
public MaleStudent() {
list = new ArrayList<>();
System.out.println("[" + Thread.currentThread().getName() + "] MaleStudent()");
}
public void accumulate(Student student) {
list.add(student);
System.out.println("[" + Thread.currentThread().getName() + "] accumulate()");
}
public void combine(MaleStudent other) {
list.addAll(other.getList());
System.out.println("[" + Thread.currentThread().getName() + "] combine()");
}
public List<Student> getList() {
return list;
}
}
package sec11.stream_collect;
import java.util.Arrays;
import java.util.List;
public class MaleStudentEx {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(
new Student("홍길동", 10, Student.Sex.MALE),
new Student("홍길순", 12, Student.Sex.FEMALE),
new Student("김남", 10, Student.Sex.MALE),
new Student("김여", 8, Student.Sex.FEMALE)
);
System.out.println("람다");
MaleStudent maleStudentListLambda = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(
() -> new MaleStudent(),
(r, t) -> r.accumulate(t),
(r1, r2) -> r1.combine(r2));
maleStudentListLambda.getList().stream().forEach(s -> System.out.println(s.getName()));
System.out.println("\n메소드 참조");
MaleStudent maleStudentListMethodReference = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);
maleStudentListMethodReference.getList().stream().forEach(s -> System.out.println(s.getName()));
}
}
람다
[main] MaleStudent()
[main] accumulate()
[main] accumulate()
홍길동
김남
메소드 참조
[main] MaleStudent()
[main] accumulate()
[main] accumulate()
홍길동
김남
Process finished with exit code 0
요소를 그룹핑해서 수집
collect()메소드는 단순히 요소를 수집하는 기능 이외에 컬렉션의 요소들을 그룹핑해서 Map 객체로 생성하는 기능도 제공
Collectors.groupingBy() 의 리턴 객체를 매개값으로 대입
Thread Safe하지 않은 Map 생성(싱글스레드에서 사용)
Collectors.groupingByConcurrent()의 리턴 객체를 매개값으로 대입
Thread Safe한 concurrentMap 생성(멀티스레드에서 사용)

학생의 성을 키(Key)로해서 남학생 List와 여학생 List가 저장된 Map 얻기
groupingBy(Function<T, K> classifier) 사용
아래 처럼 groupingBy(Student::getSex)를 이용하면, getSex()가 리턴하는 키값에 따른 Map 객체가 생성된다. 여기서는 MALE과 FEMALE을 key로 하는 그룹핑 된 Map객체가 생성된다.
Map<Student.Sex, List<Student>> mapBySex = totalList.stream
.collect(Collectors.groupingBy(Student::getSex));학생의 거주 도시를 키(Key)로해서 학생의 이름 List가 저장된 Map얻기
groupingBy(Function<T, K> classifier, Collector<T, A, D> downstream) 사용
Map<Student.City, List<String>> mapByCity = totalList.stream()
.collect(
Collectors.groupingBy(
Student::getCity,
Collectors.mapping(Student::getName, Collectors.toList())
)
);
그룹핑 수집 실습 예제
package sec11.stream_collect;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupingEx {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(
new Student("홍길동", 10, Student.Sex.MALE, Student.City.BUSAN),
new Student("홍길순", 12, Student.Sex.FEMALE, Student.City.SEOUL),
new Student("김남", 10, Student.Sex.MALE, Student.City.SEOUL),
new Student("김여", 8, Student.Sex.FEMALE, Student.City.BUSAN)
);
Map<Student.Sex, List<Student>> mapBySex = totalList.stream()
.collect(Collectors.groupingBy(Student::getSex));
System.out.println("[남학생]");
mapBySex.get(Student.Sex.MALE)
.forEach(s -> System.out.print(s.getName() + " "));
System.out.println("\n[여학생]");
mapBySex.get(Student.Sex.FEMALE)
.forEach(s -> System.out.print(s.getName() + " "));
System.out.println();
Map<Student.City, List<String>> mapByCity = totalList.stream()
.collect(
Collectors.groupingBy(
Student::getCity,
Collectors.mapping(Student::getName, Collectors.toList())
)
);
System.out.println("\n[서울]");
mapByCity.get(Student.City.SEOUL)
.forEach(name -> System.out.print(name + " "));
System.out.println("\n[부산]");
mapByCity.get(Student.City.BUSAN)
.forEach(name -> System.out.print(name + " "));
}
}
그룹핑 후 매핑 및 집계(리덕션)
Collectors.groupingBy() 메소드는 그룹핑 후, 매핑이나 집계(평균, 카운팅, 연결, 최대, 최소, 합계)를 할 수 있도록 하기위해 두번째 매개값으로 다음과 같은 Collector를 가질 수 있다.
| 리턴타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| Collector | Collectors.mapping(Function, Collector) | 매핑 |
| Collector | Collectors.averageingDouble(ToDoubleFunction) | 평균값 |
| Collector | Collectors.counting() | 요소수 |
| Collector | Collectors.joining(...) | 문자 요소들을 연결 |
| Collector | Collectors.maxBy(Comparator) | 최대값 |
| Collector | Collectors.minBy(Comparator) | 최소값 |
| Collector | Collectors.reducing(...) | 커스텀 리덕션 값 |
| Collector | Collectors.summarizingXXX(ToXXXFunction) | XXX 타입의 합계 |
성별(Sex)을 키로, 남/여 학생평균 점수를 값으로 갖는 Map 얻기
전체 리스트에서 스트림을 얻어내고, collect()로 그룹핑을 하는데, Collectors.groupingBy()의 리턴값을 받아서 collect()의 매개값으로 제공을 하겠다는 의미이다.
Map<Student.Sex, Double> map = totalList.stream()
.collect(
Collectors.groupingBy(
Student::getSex,
Collectors.averagingDouble(Student::getScore)
)
);성별(Sex)을 키로, 쉼표로 구분된 학생 이름 문자열을 값으로 갖는 Map 얻기
성별을 기준으로 Collectors.mapping()을 사용하여 학생객체를 이름요소로 매핑하고 ,로 joining한다.
Map<Student.Sex, String> mapByName = totalList.stream()
.collect(
Collectors.groupingBy(
Student::getSex,
Collectors.mapping(
Student::getName,
Collectors.joining(",")
)
)
);
12절. 병렬 처리
병렬 처리(Parallel Operation)
멀티 코어 CPU환경에서 하나의 작업을 분할해서 각각의 코어가 병렬적으로 처리
병렬 처리의 목적: 작업 처리 시간을 줄임
자바8 부터 병렬 스트림을 제공하므로 컬렉션(배열)의 전체 요소 처리 시간을 줄여줌
동시성(Concurrency)과 병렬성(Parallelism)
동시성: 멀티 스레드 환경에서 스레드가 번갈아 가며 실행하는 성질 (싱글 코어 CPU)
병렬성: 멀티 스레드 환경에서 코어들이 스레드를 병렬적으로 실행하는 성질(멀티 코어 CPU)
병렬성(Parallelism) 구분
데이터 병렬성
데이터 병렬성은 한 작업 내에 있는 전체 데이터를 쪼개어 서브 데이터들로 만들고 이 서브 데이터들을 병렬 처리해서 작업을 빨리 끝내는 것을 말한다.
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬 처리하는 것을 말한다.
작업 병렬성의 대표적인 예는 웹서버(Web Server)이다. 웹 서버는 각각의 브라우저에 요청한 내용(다른 작업)을 개별 스레드에서 병렬로 처리한다.
병렬 스트림은 데이터 병렬성을 구현한 것이다.
멀티코어의 수만큼 대용량 요소를 서브 요소들로 나누고, 각각의 서브 요소들을 분리된 스레드에서 병렬 처리시킨다.
예를 들어 쿼드 코어(Quad Core) CPU일 경우 4개의 서브 요소들로 나누고, 4개의 스레드가 각각의 서브 요소들을 병렬 처리한다.
병렬 스트림은 내부적으로 포크조인 프레임워크를 이용한다.
포크조인(ForkJoin) 프레임워크
포크조인 프레임워크 동작 방식
포크 단계
데이터를 서브 데이터로 반복적으로 분리한다.
서브 데이터를 멀티 코어에서 병렬로 처리한다.
조인 단계
서브 결과를 결합해서 최종 결과를 만들어 낸다.
실제로 병렬 처리 스트림은 포크 단계에서 차례대로 요소를 4등분하지 않는다. 이해하기 쉽도록 하기 위해 옆 그림은 차례대로 4등분 했지만, 내부적으로 서브 요소로 나누는 알고리즘이 있기 때문에 개발자는 신경쓸 필요가 없다.
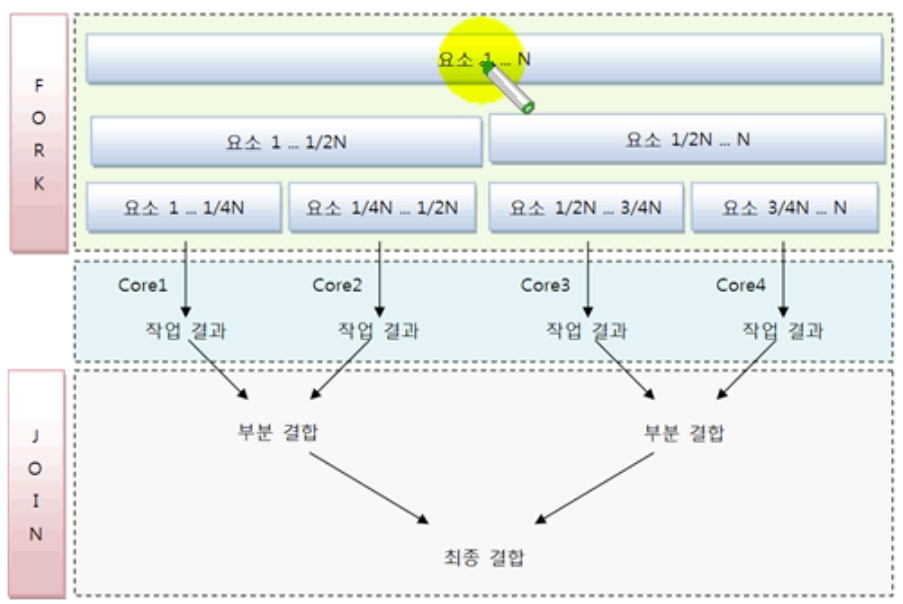
포크조인풀(ForkJoinPool)
각각의 코어에서 서브 요소를 처리하는 것은 개별 스레드가 해야하므로 스레드 관리가 필요하다.
포크조인 프레임워크는 ExecutorService의 구현 객체인 ForkJoinPool을 사용해서 작업 스레드를 관리한다.
병렬 스트림 생성
| 인터페이스 | 리턴타입 | 메소드(매개변수) |
|---|---|---|
| java.util.Collection | Stream | parallelStream() |
| java.util.Stream | Stream | parallel() |
| java.util.IntStream | IntStream | parallel() |
| java.util.LongStream | LongStream | parallel() |
| java.util.DoubleStream | DoubleStream | parallel() |
parallelStream()
컬렉션으로부터 병렬 스트림을 바로 리턴
parallel()
순차 처리 스트임을 병렬 스트림으로 변환해서 리턴
병렬 스트림의 예
11절 수집 - 사용자 정의 컨테이너에 수집하기(순차 처리 스트림)
MaleStudent 객체는 하나만 생성
남학생일 결루 accumulate()가 호출되어 MaleStudent 객체 내부에 계속 누적
combine() 메소드는 전혀 호출되지 않음
MaleStudent maleStudent = totalList.Stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);병렬 스트림으로 수정
코어의 개수 만큼 전체 요소는 서브 요소로 나뉘어지고, 해당 개수 만큼 스레드가 생성된다.
각 스레드는 서브 요소를 수집해야하므로 4개의 MaleStudent 객체를 생성하기 위해 collect()의 첫번째 메소드 참조인 MaleStudent::new를 4번 실행시킨다.
각 스레드는 MaleStudent 객체에 남학생 요소를 수집하기 위해 collect()의 두번째 메소드 참조인 MaleStudent::accumulate를 매번 실행시킨다.
수집 완료된 MaleStudent는 (코어 개수 - 1) 번의 결합으로 최종 수집된 MaleStudent로 만들어 진다. 따라서 collect()의 세번째 메소드 참조인 MaleStudent::combine() 이 (코어 개수 -1)번 실행된다.
MaleStudent maleStudent = totalList.parallelStream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);병렬 스트림 실습 예제
package sec12.stream_parallelism;
import sec11.stream_collect.Student;
import java.util.ArrayList;
import java.util.List;
public class MaleStudent {
private List<Student> list;
public MaleStudent() {
list = new ArrayList<>();
System.out.println("[" + Thread.currentThread().getName() + "] MaleStudent()");
}
public void accumulate(Student student) {
list.add(student);
System.out.println("[" + Thread.currentThread().getName() + "] accumulate()");
}
public void combine(MaleStudent other) {
list.addAll(other.getList());
System.out.println("[" + Thread.currentThread().getName() + "] combine()");
}
public List<Student> getList() {
return list;
}
}
package sec12.stream_parallelism;
import sec11.stream_collect.Student;
import java.util.Arrays;
import java.util.List;
public class MaleStudentEx {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(
new Student("홍길동", 10, Student.Sex.MALE),
new Student("홍길순", 12, Student.Sex.FEMALE),
new Student("김남", 10, Student.Sex.MALE),
new Student("김여", 8, Student.Sex.FEMALE)
);
System.out.println("람다");
MaleStudent maleStudentListLambda = totalList.parallelStream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(
() -> new MaleStudent(),
(r, t) -> r.accumulate(t),
(r1, r2) -> r1.combine(r2));
maleStudentListLambda.getList().stream().forEach(s -> System.out.println(s.getName()));
System.out.println("\n메소드 참조");
MaleStudent maleStudentListMethodReference = totalList.parallelStream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);
maleStudentListMethodReference.getList().stream().forEach(s -> System.out.println(s.getName()));
}
}람다
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[ForkJoinPool.commonPool-worker-2] MaleStudent()
[main] MaleStudent()
[ForkJoinPool.commonPool-worker-3] MaleStudent()
[main] accumulate()
[ForkJoinPool.commonPool-worker-2] accumulate()
[ForkJoinPool.commonPool-worker-2] combine()
[main] combine()
[main] combine()
홍길동
김남
메소드 참조
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[main] MaleStudent()
[ForkJoinPool.commonPool-worker-3] MaleStudent()
[ForkJoinPool.commonPool-worker-2] MaleStudent()
[ForkJoinPool.commonPool-worker-3] accumulate()
[main] accumulate()
[ForkJoinPool.commonPool-worker-3] combine()
[main] combine()
[main] combine()
홍길동
김남
Process finished with exit code 0
병럴 처리 성능
병렬 처리는 항상 빠르다?
스트림 병렬 처리가 스트림 순차 처리보다 항상 실행 성능이 좋다고 판단해서는 안된다.
병렬 처리에 영향을 미치는 3가지 요인
요소의 수와 요소당 처리 시간
컬렉션에 요소의 수가 적고 요소당 처리 시간이 짧으면 순차 처리가 오히려 병렬 처리보다 빠를 수 있다. 병렬 처리는 스레드풀 생성, 스레드 생성이라는 추가적인 비용이 발생하기 때문이다.
스트림 소스의 종류
ArrayList, 배열은 랜덤 액세스를 지원(인덱스로 접근)하기 때문에 포크 단계에서 쉽게 요소를 분리할 수 있어 병렬 처리 시간이 절약된다. 반면에 HashSet, TreeSet은 요소를 분리하기가 쉽지 않고, LinkedList는 랜덤 액세스를 지원하지 않아 링크를 따라가야 하므로 역시 요소를 분리하기가 쉽지 않다. 또한 BufferedReader.lines()은 전체 요소의 수를 알기 어렵기 때문에 포크 단계에서 부분요소로 나누기 어렵다. 따라서 이들 소스들은 ArrayList, 배열 보다는 상대적으로 병렬 처리가 늦다.
코어(Core)의 수
싱글 코어 CPU일 경우에는 순차 처리가 빠르다. 병렬 처리를 할 경우 스레드의 수만 증가하고 번갈아 가면서 스케쥴링을 해야하므로 좋지 못한 결과를 준다. 코어의 수가 많으면 많을 수록 병렬 작업 처리 속도는 빨라진다.
ArrayList VS LinkedList
package sec12.stream_parallelism;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class ArrayListVsLinkedListEx {
public static void work(int value) {
}
public static long testParallel(List<Integer> list) {
long start = System.nanoTime();
list.stream().parallel().forEach(ArrayListVsLinkedListEx::work);
long end = System.nanoTime();
long runTime = end - start;
return runTime;
}
public static void main(String[] args) {
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < 1000000; i++) {
arrayList.add(i);
linkedList.add(i);
}
//워밍업
long arrayListParallel = testParallel(arrayList);
long linkedListParallel = testParallel(linkedList);
arrayListParallel = testParallel(arrayList);
linkedListParallel = testParallel(linkedList);
if (arrayListParallel < linkedListParallel) {
System.out.println("성능 테스트 결과: ArrayList가 더 빠름");
} else {
System.out.println("성능 테스트 결과: LinkedList가 더 빠름");
}
}
}
성능 테스트 결과: ArrayList가 더 빠름
Process finished with exit code 0'ICT Eng > JAVA' 카테고리의 다른 글
| Java Logging Framework, LOGBack (0) | 2018.03.16 |
|---|---|
| 소스코드 배포 과정에 대한 자동화 쉘 스크립트 (0) | 2018.03.13 |
| [JAVA] Generic, 제네릭 (3) | 2017.11.08 |
| [JAVA] 자바의 멀티 스레드 (0) | 2017.10.11 |
| [JAVA] DI(Dependency Injection)를 이용한 빈 의존성 관리 (0) | 2017.09.14 |
- Total
- Today
- Yesterday
- Spring Boot
- Java
- 시간복잡도
- 순환
- vuex
- Wisoft
- ORM
- github
- 인프런
- JPA
- IT융합인력양성사업단
- 알고리즘
- Algorithm
- Raspberry Pi
- Recursion
- Vue.js
- 자바
- 라즈베리파이
- RBT
- 한밭대학교
- 젠킨스
- Spring
- 무선통신소프트웨어연구실
- 한밭이글스
- 스프링부트
- 레드블랙트리
- 정렬
- springboot
- vuejs
- AWS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |